Chapter 16.2: Translation Software

Interpreter
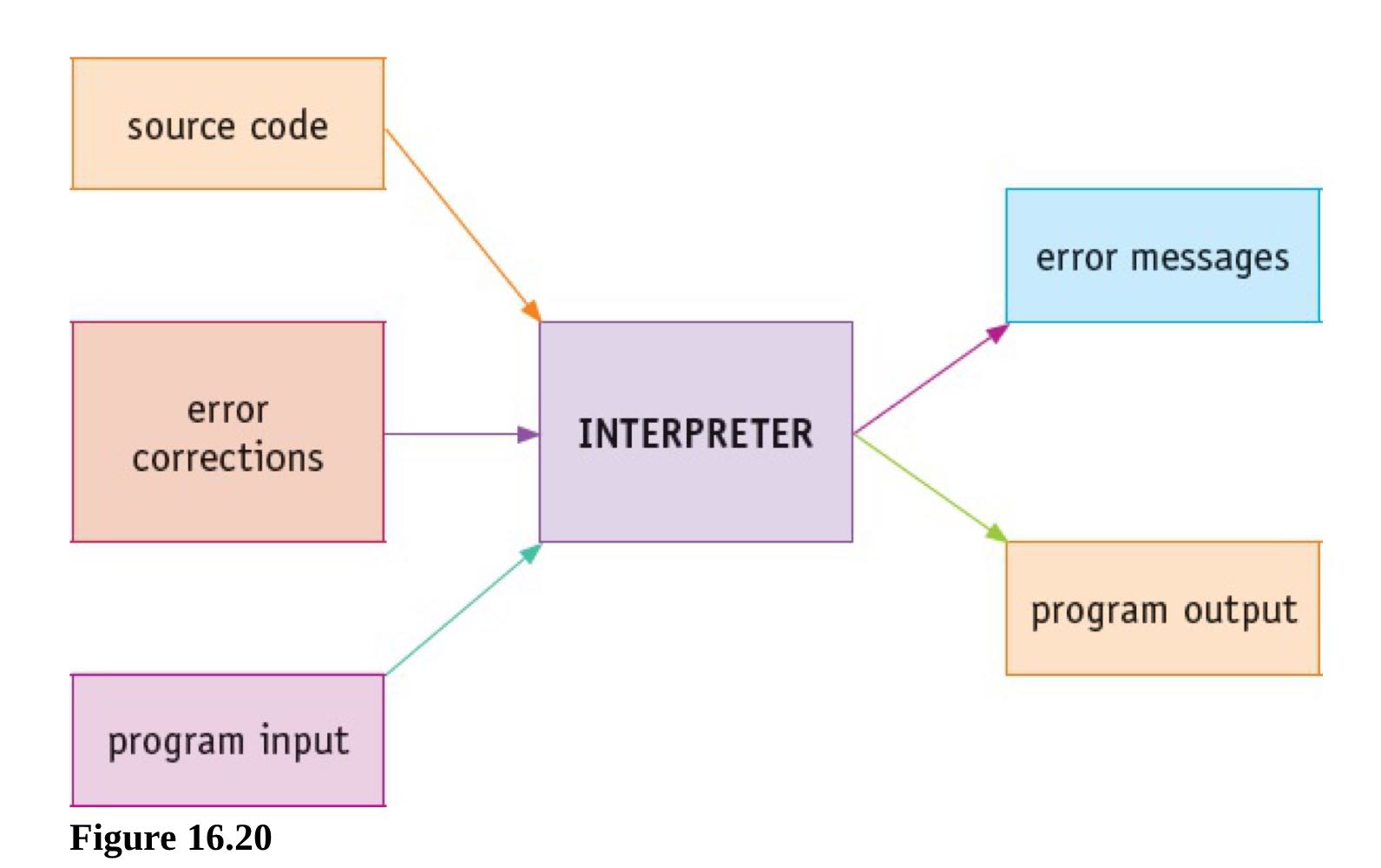
How an interpreter can executes the program without producing a complete translated version
- An interpreter examines source code one statement at a time
- Check each statement for errors
- If no error is found, the statement is executed
- If an error is found, this is reported and the interpreter halts
- Interpretation is repeated for every iteration in repeated section of code/ in loops
- Interpretation repeats every time the program runs
Why debug with interpreter
- Debugging is faster
- Can debug incomplete code
- Better diagnostics
Compiler
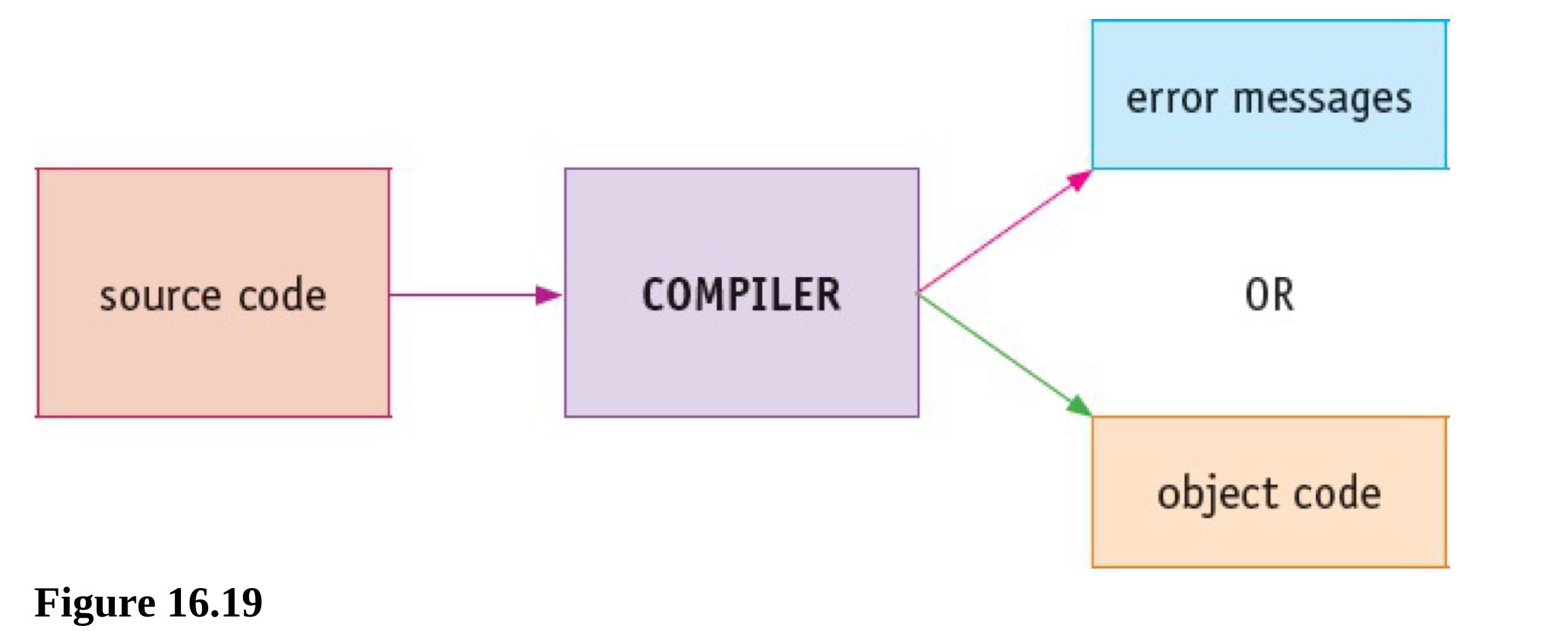
Compilation stages
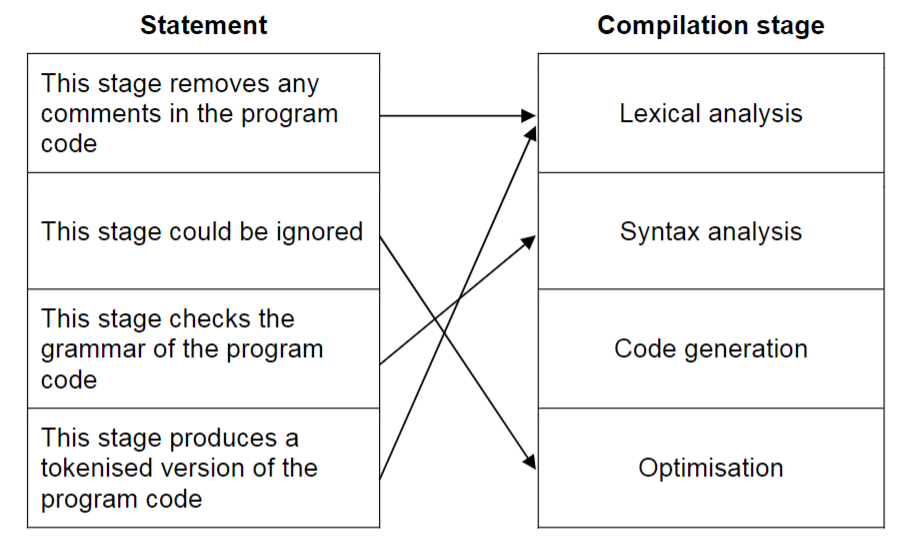
Lexical analysis
All necessary characters not required by the compiler, such as the white space and comments, are removed
The white space removed // redundant characters are removed // removal of comments // identification of errors
Tokenization
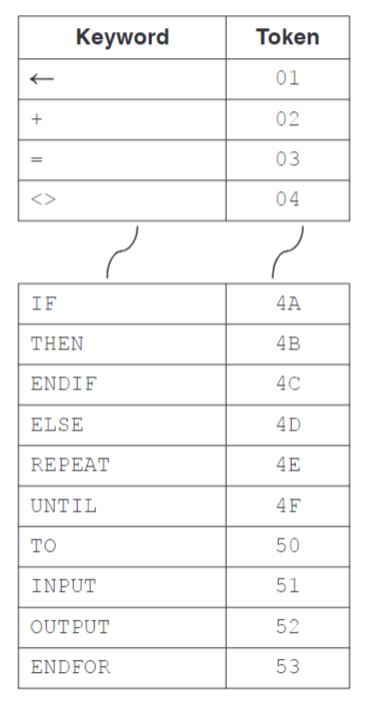
- Using a keyword table that contains all the tokens for reserved keywords and symbols
- Convert the source program into tokens
- Keyword table
- The reserved keyword used
- The operator used
- Their matching token
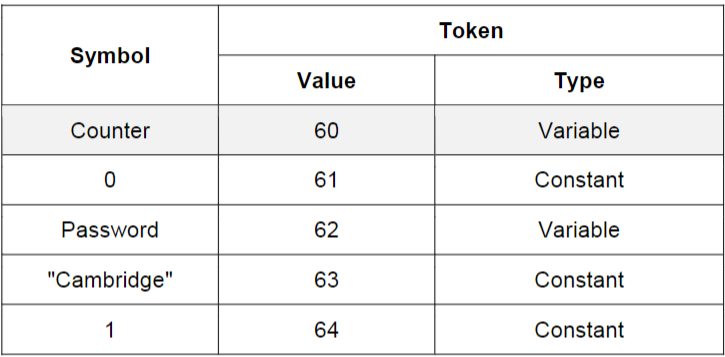
Variables, constants, and identifiers added to a symbol table, and are then converted into locations/address
- Symbol table
- Identifier name used
- The data type
- Role: e.g. Constant, array, procedure
- Location marker, value of constant
- Symbol table
Explain how the keyword table and symbol table are used to translate the source code program
- Keywords are looked up in the keyword table
- They are represented by tokens
- Identifiers are looked up in the symbol table
- They are converted into location/address
- Used to create a sequence of tokens (for the program)
Syntax analysis
- Output from the lexical analysis is checked for grammatical/syntax errors -
parsing - The rules for
parsingcan be set out in Backus-Naur form(BNF) notation - If errors are found: each statement and the associated error is outputted, but the next stage, code generation, will not be attempted
- If no error is found: passed to the next stage of compilation
--- Construction of a parse tree / parsing
- Checking that the rules of grammar/syntax have been obeyed
- Production of an error report
Code generation
- Produces an object program to perform the task defined in the source code
- The object program is in machine-readable form(binary):
- Either in machine code that can be directly executed by the CPU
- Or in intermediate code that is converted into machine code when the program is loaded
Optimization
- Performing the task using the minimum amount of resources
- Execution time, storage space, memory, and CPU use.

Why code is optimized:
- Redundant code removed
- Program requires less memory
- Code reorganized to make it more efficient
- Program will complete task in a shorter time
Why optimization is necessary
- Optimisation means the code would have fewer instructions
- Optimised code occupies less memory in space
- Fewer instructions reduce the execution time of the program
Benefits
- Code has fewer instructions/occupies less memory in space
- Shortens the execution time for the program // time taken to execute whole program decreases
Past-paper questions

- Remove the second instances of LDD 436 // remove line 04
- Remove the second instance s of ADD 437 // remove line 05
- The value required is already stored in the accumulator
Why compiled version helps protect the security of the source code
- Compiler produces executable version - not readable
- Difficult for reverse engineering
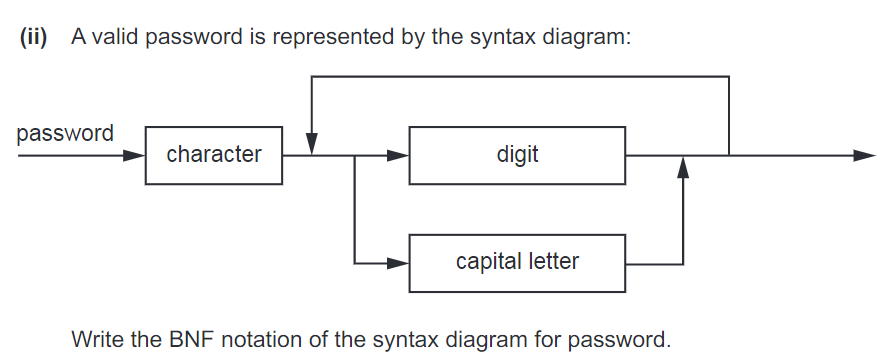
BNF & Syntax diagram
Past-paper questions
1.

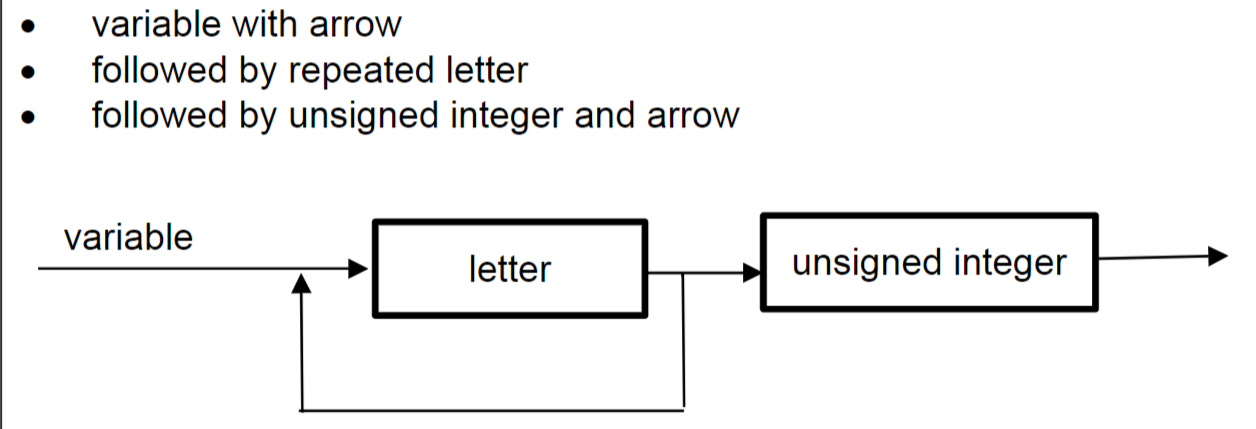
2.
![]()
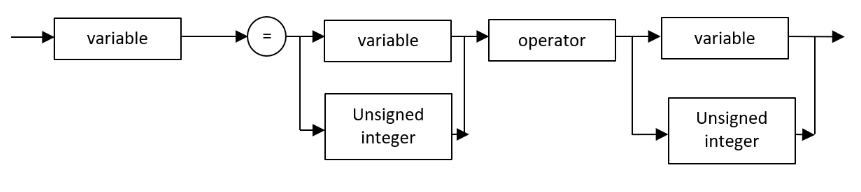
3.

Reverse Polish notation
Infix notation: operators are in between their operands
Postfix notation / Reverse Polish notation: Operators are written after operands
Prefix notation / Polish notation: operators are written before operands
🔗:Understanding infix, postfix, and prefix - lecture note from university of manchester
Why RPN can be used to evaluate expressions:
- Reverse polish notation provides and unambiguous method of representing an expression
- Reading from left to right
- Without need to use bracket
- With no need for rules of precedence
Explain how RPN is used by an interpreter to evaluate expression:
- Expressions are always evaluated from left to right
- Each operator uses two previous values on the stack
- Pushing and popping identifiers on a stack
Data structure to evaluate an expression in RPN
- Stack
- The operands are popped from the stack in reverse order to how they were pushed
- Binary tree
- Allows both infix and postfix to be evaluated (tree traversal)
Describe the main steps in the evaluation of a Reverse Polish Notation(RPN) expression using a stack
- Working from left to right in the expression
- If element is a number, push that number into stack
- If element is an operator, then pop the first two numbers on the stack
- … perform that operations on these two numbers
- PUSH result back into stack
- END once the last item in the expression has been dealt with
One advantage of the use of RPN is that evaluation of expressions does not require rules of precedence; Explain this statement
- Rules of precedence means different operators have different priorities; for example multiplication is done before addition
- In RPN, evaluation of expression is from left to right // operator are used in the sequence in which they were read
- No need for brackets // infix may require brackets
Write the Reverse Polish Notation for the following expressions
(A+B)*(C-D)
- AB+
- CD-*
Full answer: AB+CD-*
((-A/B)*4)/(C-D)
- A-
- B/4*
- CD-/
Full answer: A-B/4*CD-/
Evaluation of RPN
